
The Overlooked Part of Enterprise Data Warehouse Migrations
-4.png)
Many corporations these days face the difficult task of migrating data from old systems to new systems. This typically entails using a proliferation of third-party tools and armies of developers to manually migrate data and code from legacy sources such as Teradata and Netezza to target cloud providers such as Amazon Redshift, Google BigQuery, and Snowflake. Of course, corporations may have decades of code and data stored on their legacy platforms, so migrating this data (code) quickly and securely becomes an extremely large undertaking.

One thing that is often overlooked in this process are the ETLs (Extract, Transform, Load). We’ll explain the ETL process in more detail below, but they are basically the “pipelines” that connect each application to a central data warehouse or data lake. These pipelines allow for data migration, sharing the source database from each tool across the entire system.
In this article, we’re going to give a basic outline of ETLs, explain why they are so often overlooked when planning a data migration project, and also explain how to ensure your legacy ETL pipelines are properly migrated to the new cloud platform:
What is an ETL?
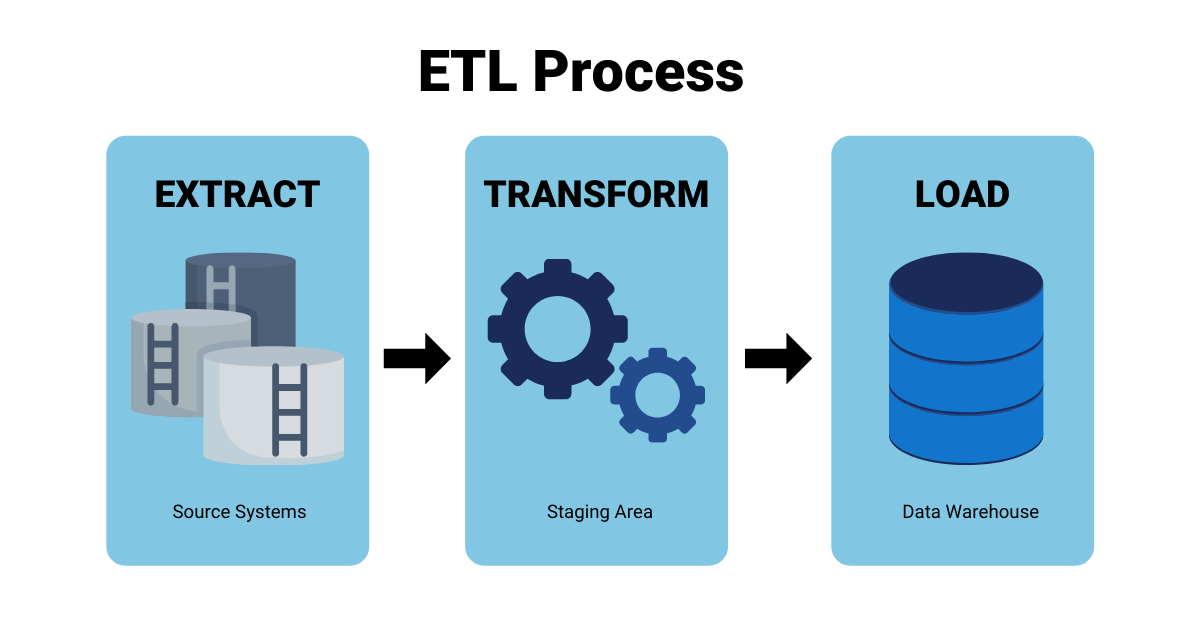
First thing’s first, let’s start with the basics of using the ETL process for database migration. What exactly is ETL? ETL stands for Extract, Transform, Load. To better understand this, let’s understand each term in turn:
- Extract: Extraction is the pulling of source data from the original database or data source system. The data is pulled and goes into a temporary staging area.
- Transform: Transformation means that the structure of the extracted source system information is changed. It is changed so that it integrates with the data within the target data system.
- Load: Once the structure is compatible with the target data system, it is deposited or “loaded” into the new destination database.
Basically, the data is extracted from a source database, changed to fit a new data source, and loaded into it.
Why Are ETLs Important?
Now that we understand the basics of ETLs, why is an ETL solution so important to a business? Basically, ETLs allow a way for various data sources to share data in an open source format, and perform relational functions. This provides a deep understanding of the context of the business overall. It’s essentially a “consolidated” look at the business overall, which makes it easier for members of the business to analyze and report on data relevant to their initiatives.
ETL functions basically codify the processes that move data between data systems. This makes it so a new code or script doesn’t have to be written each time. On top of this, ETL code is relatively easy to write for a data professional. As a result, businesses typically have many ETL functions tying their data sources together, especially with the proliferation of commercial and open-source ETL tools on the market.
Moreover, ETL functions can be used across the organization to perform typical relational data functions. Queries such as:
- Are the overall sales rising or falling?
- How are different managers spending the budget?
- Are there any current trends in service calls?
ETL tools continue to evolve as well. Modern ETL tools now support emerging integration requirements for things such as streaming data.
Overall, organizations use an ETL solution to bring data together from across the organization. It is vital in maintaining accuracy, and to provide the auditing required for data warehousing, reporting, and analytics.
Why Are ETLs Often Overlooked in Migrations?
So now that we understand why ETLs are so important, why are they so often overlooked in a migration strategy?
The simple answer is that migrating ETLs is a difficult and massive task. When migrating your in-house data environment to the cloud, there’s not simply a button to unplug and repoint legacy data ETL programs.
Companies are “blocked in” their migration efforts when they are stuck on an older version of their tools (such as Informatica, DataStage, or others). Companies already have a migration process underway, and they don’t want to increase the risk by upgrading ETL functions at the same time.

How Do You Migrate ETLs To The Cloud?
So now that we understand the importance of ETL, as well as the difficulty of migrating it to the cloud, what’s the best solution?
The best method of migrating ETL to the cloud is through automation. This is the quickest and most cost-effective method of doing so. Automation works in two ways:
Automation Defines the ETLs
Automation programs work by automatically scanning through your complete inventory of legacy ETL pipelines. Then, they uncover the lineage, and the source-to-target data flow.
The automation discovers and outlines the following areas:
- Identifying what and how many pipelines are feeding the data warehouse
- The source systems that are feeding the data warehouse
- Identifying pipelines feeding other systems.
Basically, the automation programs provide a full outline of your ETL pipelines which can be migrated to the cloud. With this info, customers can get quick, actionable insights to plan their migration, without risking impacting their business or other systems which depend on the ETLs.
Automation Translates the ETL Code
Once automation has scanned the ETL code and defined the pathways for migration purposes, it can also work to translate the legacy ETL code to run natively against the cloud target.
It can translate all embedded SQL to the syntax of the target cloud platform. It can also convert all XML objects, including source/target connectors, tables, and orchestration logic to run against the cloud platform.
There’s no denying that ETLs are a complicated are of business. But they are also an extremely important connecting pipeline in many organizations. When planning a migration to the cloud, corporations want to get their legacy ETL pipelines running on the cloud efficiently without impacting current business processes.
Automation can greatly help with this task. It takes ETL pipelines off the critical path, and enables your team to have more time and resources to focus on your migration as a whole. Our SHIFT™ Migration Suite provides end-to-end legacy ETL Migration. Learn more today.